Automate content at scale: get insights from trusted sources

Many methods exist to generate content, including natural language generation from numerical data. Despite all the attractiveness of computational linguistics, our work will lead us to generate content through summarization algorithms.
Before anything, it should be understood that this tool was not designed to replace the editorial work itself. The initial objective was to create a tool to generate a first editorial draft on specific subjects or by lack of expertise (unless you know by heart how a chainsaw works or you know all the necessary steps to install a glass roof in a kitchen…).
It is therefore a question of generating summaries on thematic multi-documents. Summarizing a text is very difficult because as humans, to summarize a text, we usually read it entirely to develop our understanding then we write a summary highlighting its main points. So we can save time through automation.
The objective is therefore to generate summaries automatically, similar to summaries written by humans. The most complex task is to introduce semantics, a criterion for judging quality by humans and not controlled by computers (the tool developed does not yet contain this feature. You are told if you want to test it 🙂 ).
Step 0: main features
- Content is scraped on a specific SERP (google.co.uk, google.es …) in response to a request for specific information on a topic, formulated by the user.
- Specific processing is performed to extract only the thematic content.
- For each paragraph identified, an importance score is calculated.
- Semantically close-related paragraphs are grouped together.
- Content is translated.
Step 1: retrieving existing content
The structure of the SERP highly is important. Before starting to generate content, you need to study how the results are displayed and which pages are positioned on the first two pages of results (because it is those pages that we will extract) in order to understand how to write your query in the tool.
Step 2: extract content with high added value
For a given request, we must retrieve content in order to process it in order to extract only the substantial marrow. This means not taking into account certain sites such as forums, YouTube pages, Amazon list pages, etc. Processing also involves getting rid of semantic noise: text elements without a direct link with the content linked to the query (text elements attached to the navigation, irrelevant paragraphs, etc.).
Also, depending on the localities, the quality of the content may differ. For example, Belgians will tend to have better quality content on beer (and not on football) than French people, etc. We therefore took this component into account in order to retrieve the content in the “right” place.
Construct an intermediate representation of the input text that expresses the main aspects of the text
Each summary system creates an intermediate representation of the text it intends to summarize and finds the overriding content based on that representation.
Topic representation
The topic representation can be done through frequency measurement or via a Bayesian approach.
With regard to frequency measurements, we find the probability of a word, and a well-known concept: the TF-IDF.
Many multi-document summary methods have limitations, including considering sentences as independent of each other. The context is therefore not taken into account. This is where the Bayesian statistical approach comes in. Bayesian models are probabilistic models that allow us to discover the subjects of documents. They are quite powerful because they represent information that is lost in other approaches. The advantage lies in taking into account the differences and similarities of the multi-documents used for the summary.
Indicators representation
Indicator representation approaches aim to model the topic representation from a set of characteristics and use them to directly classify sentences rather than represent the subjects of the input text. Graphical methods and machine learning techniques (including Bayesian naive classification) are often used to determine important sentences to include in the summary.
Step 3: determine a score of importance
In multi-document representation approaches, the importance score represents how well the sentence explains some of the most important topics in the text. In most methods, the score is calculated by aggregating evidence from different indicators. Moreover, machine learning techniques are often used to find weights for indicators.
We will look at different summary techniques, which you can use, as you wish, via the tool.
Latent Semantic Analysis
My favorite method 🙂 It appeals to the processing of natural languages which involves linguistics and artificial intelligence. This method also uses vector representation of documents, introduced by Gérard Salton.
A matrix is used here that cross-references the occurrences between terms and multi-documents.
Luhn
Named after Hans Peter Luhn, an engineer at IBM in the 1940s (I take advantage of this temporal focus to advise you to read on the advances in linguistics and language processing techniques in those years).
This method gives a score to sentences according to the frequency of words in multi-documents.
Edmundson
Harold Edmundson developed Luhn’s method by incorporating in the scoring of sentences, index words and the position of sentences in multi-documents. It has developed three dictionaries of positive, negative and neutral index words.
LexRank
The approach is based on the concept of vector centrality in a graphical representation of sentences. In this model, a connectivity matrix based on the similarity of the intra-phrase cosine is used as the contiguity matrix for the graphical representation of sentences.
…
If I tell you that the LexRank summary technique is related to the PageRank concept, it will necessarily interest you more. Indeed, the LexRank calculation method is directly inspired by the PageRank method.
To ensure that the similarity matrix is always irreducible and aperiodic, Larry Page (1998, 4. Convergence properties) suggests reserving a low probability for bouncing to any node in the graph.
A random walk on a graph is a stochastic process where at any given time step we are at a particular node of the graph and choose an outedge uniformly at random to determine the node to visit at the next time step.
If we attribute a uniform bound probability to any node on the graph, we have the version of the equation known as PageRank.
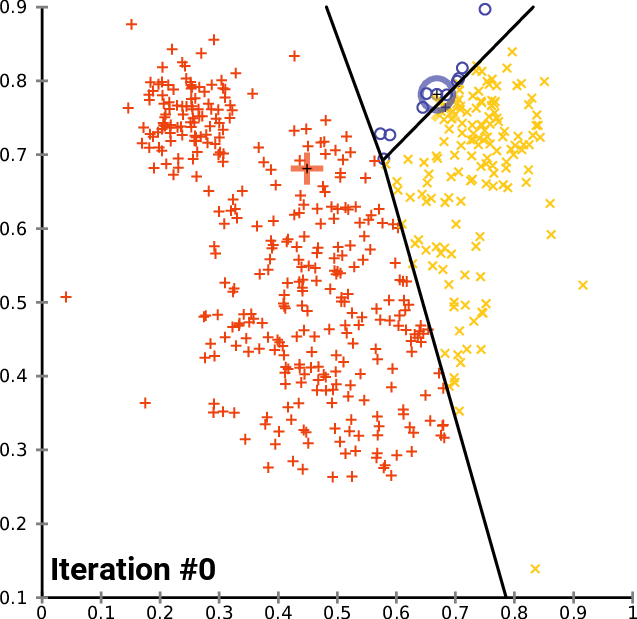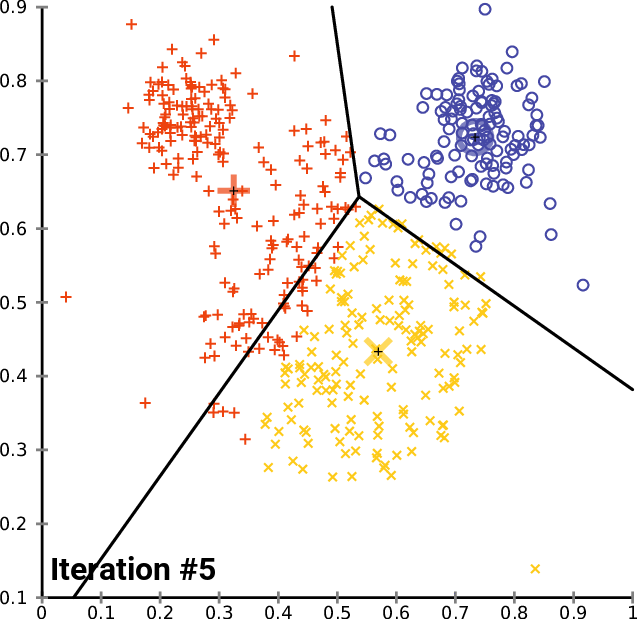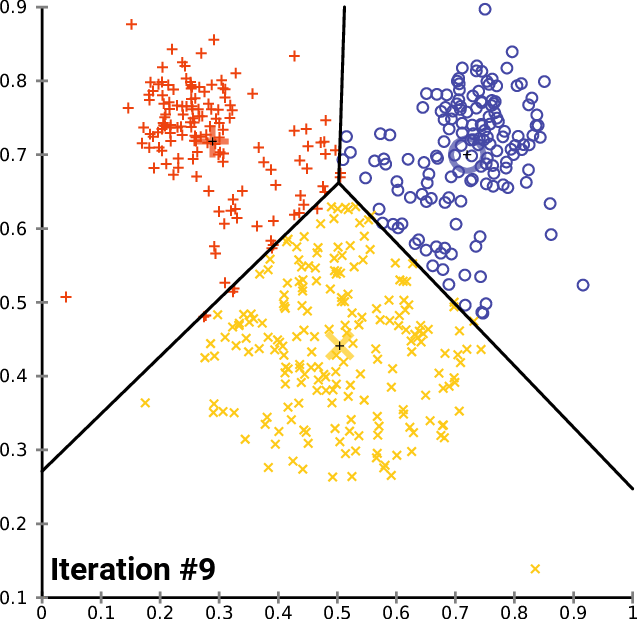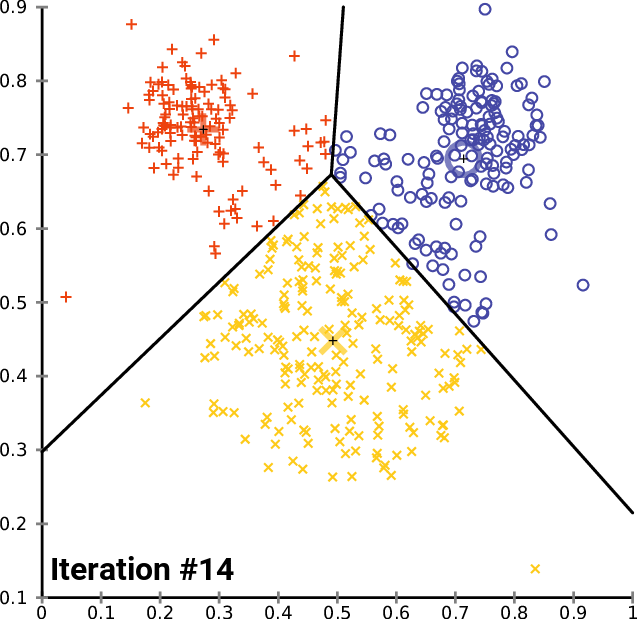
Step 3: Grouping paragraphs
Using the doc2vec method
The principle is to produce a digital representation of documents, regardless of the volume of content they contain. The document vector is intended to represent the context of a document.
Use of the k-means method
This method allows us to combine paragraphs into K groups under the same label.
Step 5: content translation
We use TextBlob, which itself uses the Google Translation API. The results, as you will see during your tests are satisfying, although some terms are sometimes mistranslated.
Installing and using the tool
Unzip the archive you just downloaded, and place it on your desktop.
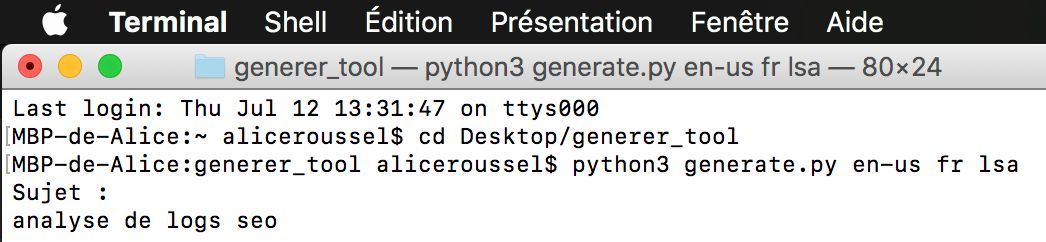
Then open the terminal and enter the following commands:
pip install -r requirements.txt
# This allows you to quickly install all required libraries
python -c "import nltk; nltk.download('punkt')"Then, join the “generer_tool” directory and run the following command :
python3 generate.py [lang_src] [lang_tar] [methode][lang_src] refers to the language in which you want to retrieve the content. The following languages are available: fr, es, de, en-uk and en-us.
[lang_target] refers to the language in which you want the content to be generated: fr, en, es, de.
And finally, [method] refers to the summary method you wish to use among those described above: Luhn [luhn], LSA [lsa], Edmundson [edm] and LexRank [lex].
Wait a few seconds and retrieve the “search-name.txt” file in the “data” subfolder.
Upgrades to come
Beyond the improvements we can make to the content generated as such, we will now be interested in scraping Google Shopping data (this echoes Erlé’s June 2017 conference at Web2Day) in order to extract product-related features, etc..

The development of this tool was done in collaboration with Pierre, a brilliant student in Data Science.



Comments ()