Automate ALT attributes with Tensorflow

Developed by engineers assigned to the Google Brain team within Google’s Artificial Intelligence division, TensorFlow is an open source framework (since 2015) dedicated to machine learning. It is one of the most widely used tools in the field of machine learning.
I will present an example of image and video recognition for SEO. As you can imagine, the aim here is to automate (or semi-automate, we will see that human processing remains necessary) the optimization of image and video files.
Installing Tensorflow
TensorFlow can be installed in different ways but in our case we install it via the native function: $pip.
We consider that Python is installed on your machine but, if need be, I can help you in the installation (just drop me a line).
$ pip install tensorflowOnce the installation is finished, we need to install the necessary libraries:
$pip install Cython
$pip install pillow
$pip install lxml
$pip install jupyter
$pip install matplotlibThen download the Github archive “models” from Tensorflow.
We then need to install the Protobuf library (developed by Google, and used in particular for internal inter-machine communications. Messages are serialized in binary format). Download the “protoc” archive, version 3.4.0.
The archives must be displayed in the same folder as below:
Then enter the following command:
export PATH=$PATH:/Users/aliceroussel/Desktop/videorecognition/protoc/binStill in the terminal, we place ourselves in the “research” folder:
cd /researchprotoc object_detection/protos/*.proto –python_out=.Then, it is necessary to recover the notebook “object_detection_tutorial.ipnyb” (I share it with you via my Drive), and replace the existing notebook which is in the directory :
videorecognition/models/research/object_detection/Installation is now complete 🙂
When I first installed it, it was necessary to use an earlier version of TensorFlow for it to work but now it works with version 1.8.
Image detection
We now get to the heart of the matter with, as a first step, image recognition. We run the following command:
jupyter notebookThen we open the notebook that interests us:
All sections are then executed until “Detection”. They are necessary for importing libraries and preparing the object recognition model provided.
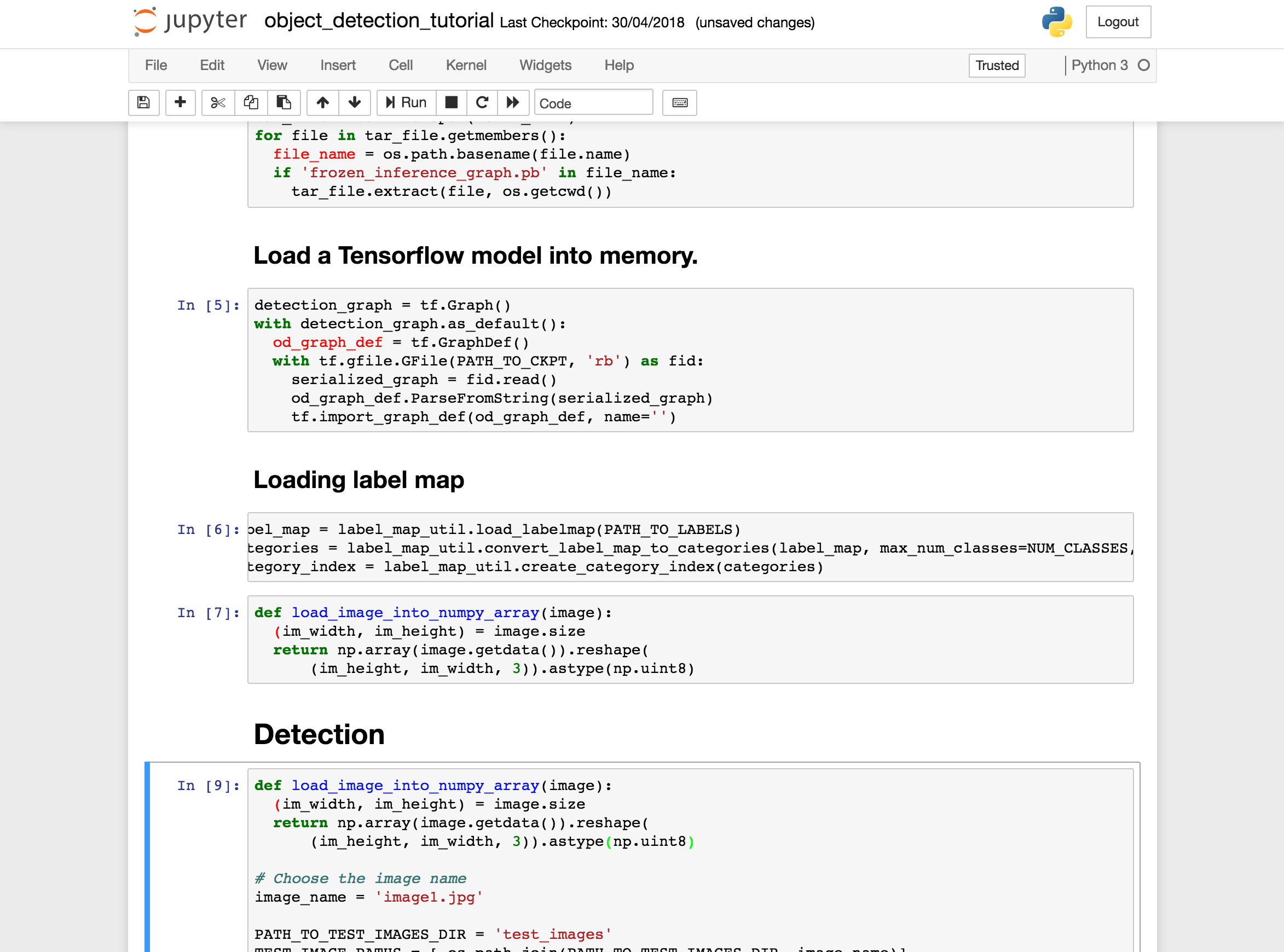
Then, you must indicate in the directory /videorecognition/models/research/object_detection/test_images/ the images you want to analyze. For my part, I chose an image from a Sézane product sheet (interesting example when the objective is to automate the optimization of ALT attributes and image file captions on an ecommerce site).
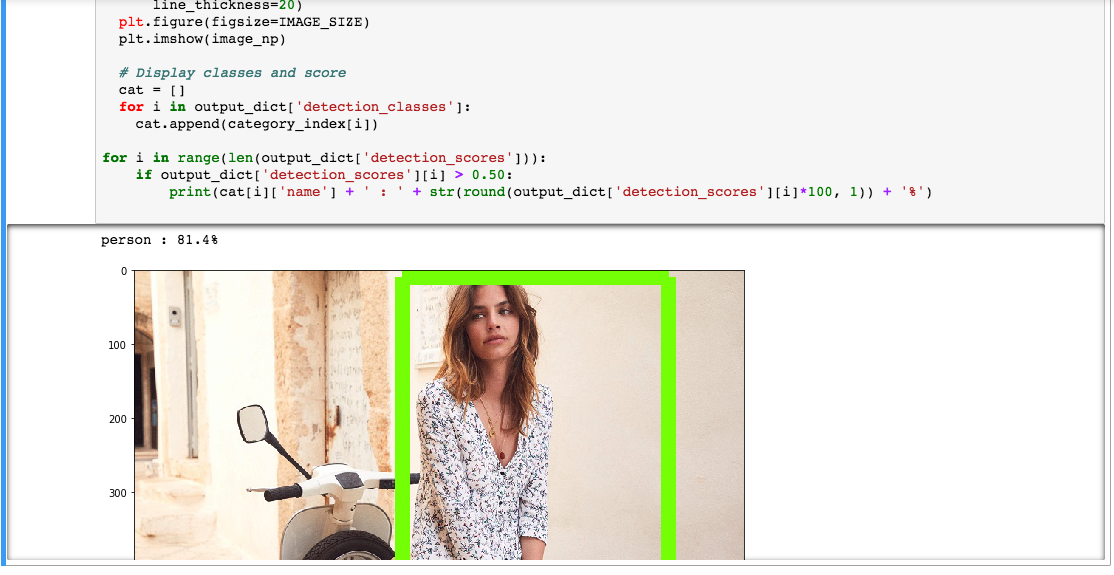
On the result above, we note that only the person is recognized at 81.4%. Obviously, the model does not stop there (otherwise, our objective would not be reached) but allows indeed to identify other elements. In this case, it is the type of clothing worn by the person that would interest us. Having done the test with a chair, the model manages to classify it as a “barber chair”. One can note the accuracy of the identification (in this case the associated long tail).


Video recognition
The objective here would be to generate a description of the video, complete or not, in order to work the referencing of the video on YouTube. You can also imagine combining this feature with speech recognition to, for example, generate a subtitle file. For the illustration, I chose a video from the French Open tournament with my favourite tennis player: Roger Federer. 🙂
So we execute the following section, taking care to indicate the path to the video :
# mp4 format
cap = cv2.VideoCapture(‘/Users/aliceroussel/Desktop/tennis.mp4’)The functionality is still perfectible but it is a good start, and it would be necessary to work on a specific learning base for a type of video or images in order to perfect the optimization of images and videos.
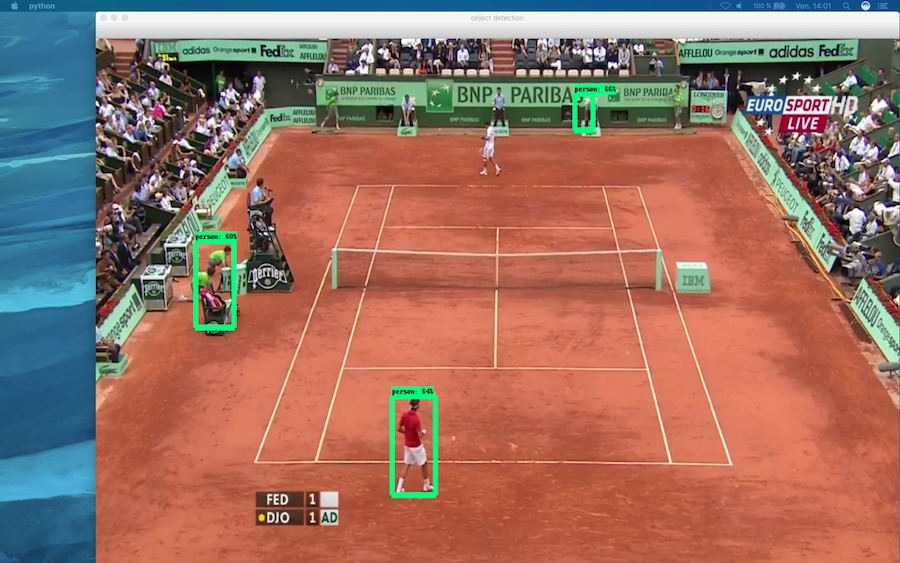
Finally, video recognition can also be activated via the webcam (to do this, simply comment out the path to the video). Here too, the model can be improved and there is a latency time between the appearance of an object (a bottle of water for example) and its identification. Below the test with my Jack Russell:
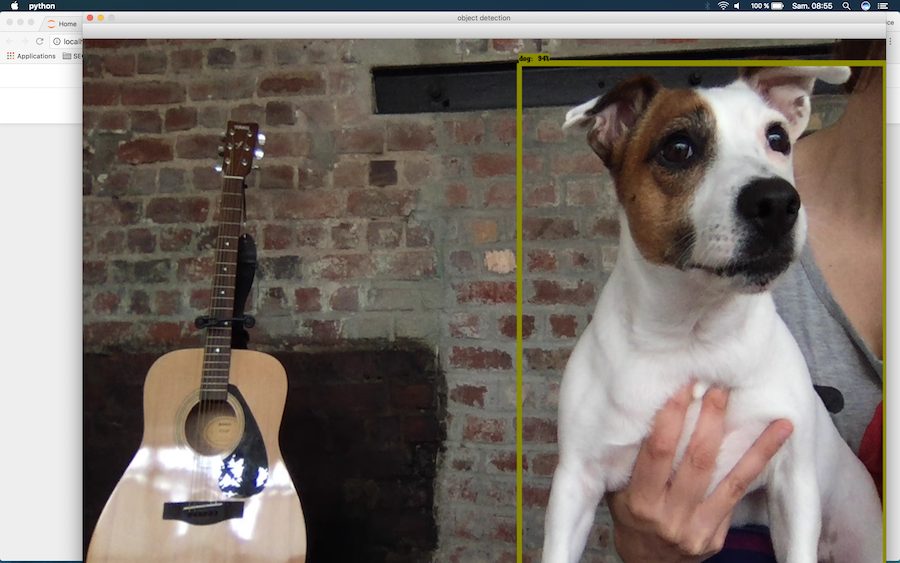
You can also use this feature through the Google Vision Kit, available at Target.
In a next article, we will evoke this time the complete automation of the entities analysis and the sentiments analysis with the construction of a crawler.
 Alice Roussel
Alice Roussel
We will see how to export the results to .xlsx format. This is obviously the most important point since it is it that allows, in the end, the semi-automatization of the process.
This article was written in collaboration of Pierre Lopez, currently in internship within my SEO team as a Data Scientist specialized in Natural Language Processing.